
[Python] 빅데이터분석 시각화 - 그래프 그리기 (Matplotlib)
Matplotlib는 그래프를 그리는 함수를 내장하고 있는 확장 라이브러리다. matplotlib.pyplot을 import하여 해당 모듈의 각 함수를 사용해 간편하게 그래프를 만들고 변화를 줄 수 있다. 기본적으로 plot()
xl-shine.tistory.com
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rc('font', family='malgun gothic')
plt.rc('axes', unicode_minus=False)
%matplotlib inline # jupyter notebook에서 그래프를 보기 위한 코드
weather = pd.read_csv('data/weather.csv', encoding='euc-kr')
weather.head() 도시 월 평균기온 최저기온 최고기온
0 서울 Jan -4.0 -7.3 0.1
1 서울 Feb -1.6 -5.9 3.3
2 서울 Mar 8.1 3.8 13.6
3 서울 Apr 13.0 8.1 18.5
4 서울 May 18.2 13.4 23.3weather['월'] = pd.to_datetime(weather['월'], format='%b').dt.month
weather_pivot = weather.pivot(index='월', columns='도시', values='평균기온')
weather_pivot도시 대구 서울 인천 철원
월
1 -0.9 -4.0 -3.8 -7.3
2 1.3 -1.6 -1.8 -4.4
3 9.2 8.1 6.9 6.2
4 15.0 13.0 11.9 11.2
5 19.2 18.2 17.0 16.8
6 23.6 23.1 21.2 21.7
7 28.2 27.8 26.6 25.4
8 27.7 28.8 28.1 26.3
9 21.0 21.5 21.6 18.8
10 14.3 13.1 13.8 9.9
11 8.8 7.8 8.5 4.5
12 2.0 -0.6 -0.2 -4.0weather_pivot.plot()
plt.title('도시별 평균기온')
plt.xlabel('월')
plt.ylabel('기온')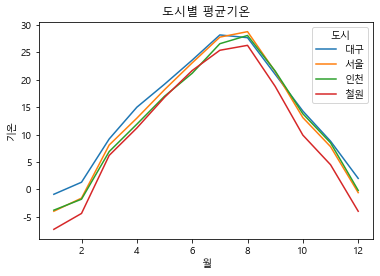
weather_pivot.plot(subplots=True, figsize=(6,6));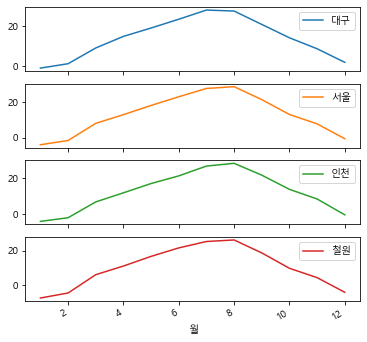
# seaborn 내장 데이터로 시각화 연습
import seaborn as sns
iris = sns.load_dataset('iris')
titanic = sns.load_dataset('titanic')seaborn은 matplotlib처럼 그래프를 그리는데 사용하는 라이브러리다. matplotlib로 구현하는 그래프가 투박한 느낌이라면, seaborn으로 그리는 그래프는 좀 더 가시성 있고 깔끔한게 특징이다. 여기서는 seaborn의 내장 데이터를 시각화 연습 자료로 활용하기 위해 호출했다.
iris sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
... ... ... ... ... ...
145 6.7 3.0 5.2 2.3 virginica
146 6.3 2.5 5.0 1.9 virginica
147 6.5 3.0 5.2 2.0 virginica
148 6.2 3.4 5.4 2.3 virginica
149 5.9 3.0 5.1 1.8 virginica# 꽃받침 길이 시각화
#iris['sepal_length'][:10].plot(kind='bar', rot=45);
iris['sepal_length'][:10].plot.bar(rot=45);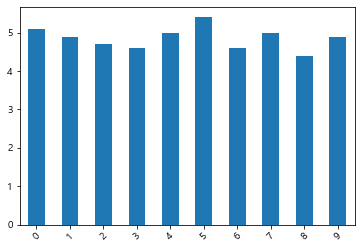
iris[:5].plot.bar();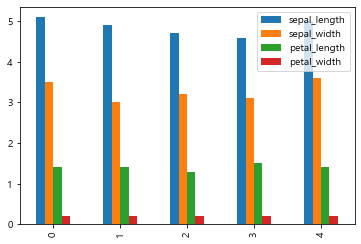
iris[:5].plot(kind='barh');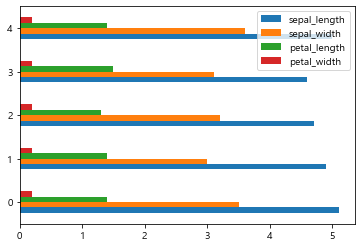
iris[:5].plot(kind='barh', stacked=True, legend=False);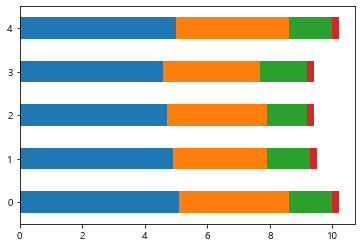
iris_df = iris.groupby('species').mean()
iris_df sepal_length sepal_width petal_length petal_width
species
setosa 5.006 3.428 1.462 0.246
versicolor 5.936 2.770 4.260 1.326
virginica 6.588 2.974 5.552 2.026iris_df.plot.barh();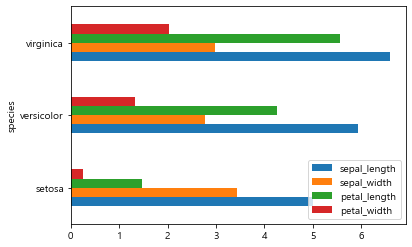
iris_df.T.plot.barh();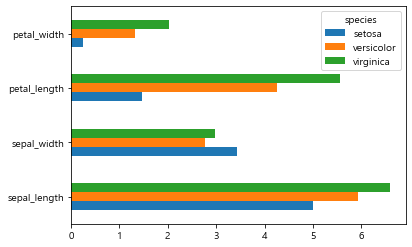
titanic['age'].plot(kind='hist');
plt.title('나이 분포')
plt.xlabel('나이')
titanic['age'].plot.hist(bins=20, alpha=0.5, edgecolor='w', color='darkred');
titanic['age'].plot.kde();
iris.plot.density()
iris.plot.box();
iris.boxplot(by='species');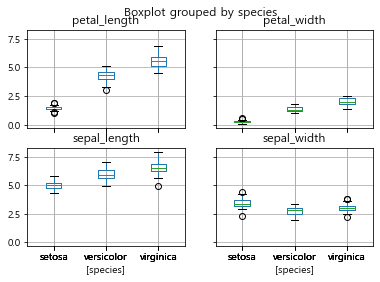
iris.plot.scatter(x='sepal_length', y='sepal_width', s=iris.petal_length*10);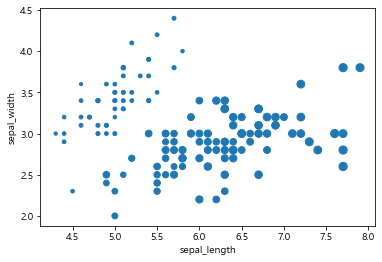
# species 값이 setosa면 r, 아니면 b
np.where(iris.species=='setosa', 'r','b')
# species 값이 setosa면 r, versicolor면 b, 둘다 아니면 g
mc = np.where(iris.species=='setosa', 'r', np.where(iris.species=='versicolor','b','g'))iris.plot.scatter(x='sepal_length', y='sepal_width', c=mc);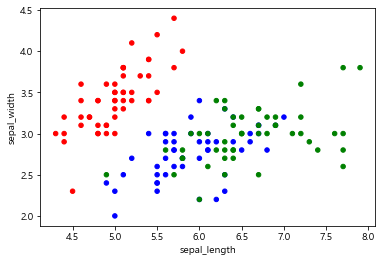
'빅데이터분석👨💻' 카테고리의 다른 글
| [Python] 수치형 변수의 시각화 - Barplot() (1) | 2023.12.27 |
|---|---|
| [Python] 범주형 변수의 빈도 시각화 - Countplot() (0) | 2023.12.26 |
| [Python] 빅데이터분석 시각화 - 그래프 그리기 (Matplotlib) (0) | 2023.12.20 |
| [Python] 빅데이터 분석 기초 - 객체 병합 함수 (concat, join, merge) (0) | 2023.12.18 |
| [Python] 빅데이터 분석 기초 - 집계 (Aggregation) (0) | 2023.11.27 |