
반응형
Selenium의 WebDriver를 사용해 크롤링하기
# 추가 패키지 설치
!pip install supabase # 수파베이스 SDK 설치
!pip install selenium # 헤드리스 브라우저를 위한 테스트 자동화 툴
!pip install beautifulsoup4 # html 파싱 툴
- 크롬 화면 우상단 ... 메뉴 버튼 클릭 → 설정 → 하단 Chrome 정보 클릭
- 크롬 드라이버 다운로드
- 아래 코드로 자신의 운영체제 및 아키텍처 확인
- https://googlechromelabs.github.io/chrome-for-testing/#stable
Chrome for Testing availability
chrome-headless-shellmac-arm64https://storage.googleapis.com/chrome-for-testing-public/124.0.6367.118/mac-arm64/chrome-headless-shell-mac-arm64.zip200
googlechromelabs.github.io
import platform
import sys, os, requests, zipfile
# 운영체제 및 아키텍처 확인
os_name = platform.system().lower()
architecture = platform.machine()
if os_name == 'darwin':
if architecture == 'arm64':
print("운영체제: macOS, 아키텍처: ARM64")
elif architecture == 'x86_64':
print("운영체제: macOS, 아키텍처: x64")
elif os_name == 'windows':
if sys.maxsize > 2**32:
print("운영체제: Windows, 아키텍처: 64-bit")
else:
print("운영체제: Windows, 아키텍처: 32-bit")
else:
print(f"운영체제: {os_name}, 아키텍처: {architecture}")chrome_driver_url = 'https://storage.googleapis.com/chrome-for-testing-public/124.0.6367.91/linux64/chromedriver-linux64.zip'- 크롬 드라이버 설치 및 작동 확인
# 다운로드
os.makedirs('./driver', exist_ok=True)
with requests.get(chrome_driver_url) as response:
with open('./driver/chromedriver.zip', 'wb') as file:
file.write(response.content)
# 압축해제
with zipfile.ZipFile('./driver/chromedriver.zip') as zip_ref:
zip_ref.extractall('./driver')
os.remove('./driver/chromedriver.zip')from glob import glob
driver_path = None
if os_name == 'darwin': # 맥 사용자
driver_path = glob('./driver/**/chromedriver', recursive=True)[0]
else: # 윈도우 사용자
driver_path = glob('./driver/**/chromedriver', recursive=True)[0]from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from bs4 import BeautifulSoup
service = Service(executable_path=driver_path)
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--blink-settings=imagesEnabled=false')
driver = webdriver.Chrome(service=service, options=chrome_options)
url = '크롤링 할 url'
driver.get(url)위의 방식대로 문제없이 진행된다면 크롤링이 성공적으로 진행된다. 하지만 나의 경우 셀레니움 버전의 문제인지 크롬 브라우저의 문제인지 WebDriver 객체를 만들 때, Chrome binary를 제대로 찾지 못하는 에러가 발생했다.
에러 내용
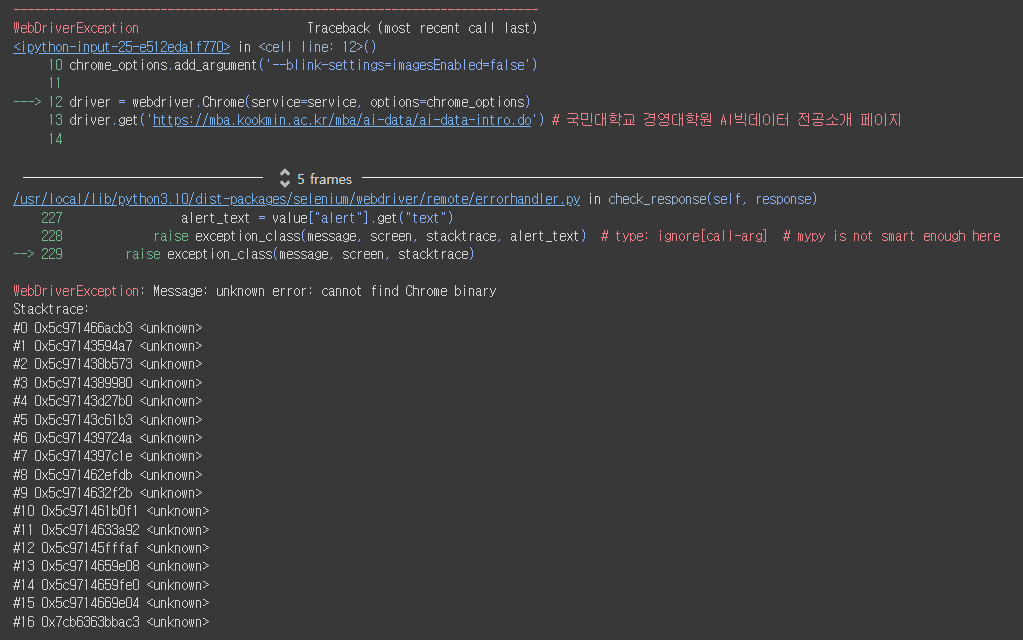
WebDriverException 발생 시 - Seleniumbase
찾아보니 selenium이 최신 버전으로 업데이트 되면서, seleniumbase 라이브러리 내 Driver 클래스를 사용해야 정상적으로 작동한다고 한다.
# 패키지 설치
!pip install seleniumbasefrom seleniumbase import Driver
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from bs4 import BeautifulSoup
driver = Driver(browser="chrome", headless=True)url = '크롤링 할 url'
driver.get(url)
print(driver) # 실행 확인# 파싱
soup = BeautifulSoup(driver.page_source, 'html.parser')
# 크롤링이 끝난후 반드시 브라우저 자원을 반납해야함.
driver.close()
driver.quit()
반응형
'개발일기 💻 > Python' 카테고리의 다른 글
| [Python] 가상환경 실행 오류 해결 UnauthorizedAccess Error (0) | 2025.01.08 |
|---|---|
| [Python] Selenium WebDriverException chromedriver PATH 에러 해결 (1) | 2024.08.08 |
| [Jupyter Notebook] Colab환경에서 ipynb 파일을 html로 추출하기 (0) | 2024.06.20 |
| [Python] AttributeError : module 'numpy' has no attribute 'ndarray' 해결 (1) | 2024.03.23 |
| [Python] OSError: [E050] Can't find model 'en_core_web_sm' 에러 해결 (1) | 2024.03.16 |