
본 포스팅에서는 Feature engineering 실습을 위해 1차적으로 가공된 타이타닉 생존자 예측 데이터를 활욯했다.
데이터 로딩
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inlinetitanic = pd.read_csv('data/titanic.csv')
titanic.info()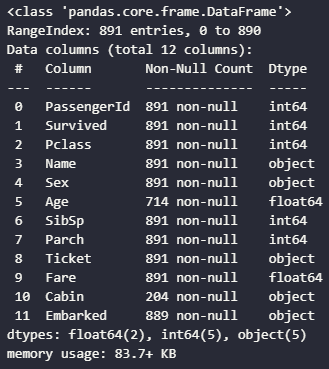
결측치 처리
titanic.isnull().mean()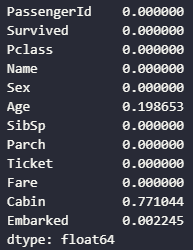
결측치를 조회해보면 Age, Cabin, Embarked라는 변수에서 결측치가 보인다. 나이는 평균으로 처리해주고, 다른 두 변수는 새로운 범주를 지정해준다. 결측치를 굳이 새로운 범주로 분리하는 가장 큰 이유는 결측치가 데이터 예측에 중요한 역할을 할 수 있을지 모르기 때문이다. 시각화 작업에서 그래프를 통해 각 범주별로 타겟 변수와의 관련성을 검증해야하는데, 이때 결측치를 그대로 냅두거나 다른 범주와 무심코 합쳐버릴 경우, 결측치가 의미하는 바를 알 수 없다. 그렇기 때문에 범주형 변수의 결측치를 처리할 때는 최대한 조심스럽게 처리해야한다.
titanic.Age.fillna(titanic.Age.mean(), inplace=True)
titanic.Cabin.fillna('UNK', inplace=True)
titanic.Embarked.fillna('UNK', inplace=True)
titanic.isnull().sum()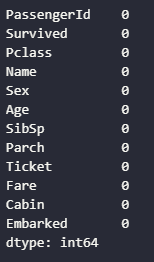
데이터 탐색
결측치를 전부 처리한 후, 범주형 데이터를 탐색할 때는 가장 먼저 describe() 함수를 통해 전체적인 통계를 확인하며 각 변수 별로 이상치를 확인해준다. 이번 예제에서는 이상치 처리는 건너뛰었다.
titanic.describe()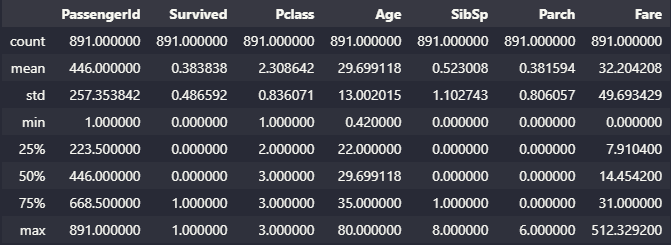
value_counts() 함수를 활용해 범주형 변수들의 범주를 육안으로 확인한다. 범주가 넓을 수록 학습시키는데 어려움이 있기 때문에 범주는 적을수록 좋다. 하지만 범주를 줄이는 과정에서 범주를 줄이는 것에만 초점을 맞춰 작업하다 중요 범주를 놓치는 실수를 해서는 안된다. 각 범주 별 타겟 변수와의 관계성을 확인한 후 해당 변수의 범주 처리 방식을 정해야한다.
titanic.Sex.value_counts()
titanic.Pclass.value_counts()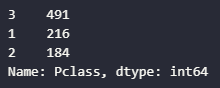
titanic.Cabin.value_counts()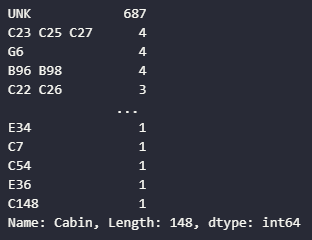
Cabin 컬럼의 경우, 선실의 종류가 워낙 많아 범주가 너무 많이 잡히는 모습을 볼 수 있다. 보이는 데이터를 통해 선실을 나누는 가장 큰 단위가 첫번째 알파벳이라는 사실을 알 수 있고, 이를 그룹핑해 해당 변수의 범주를 줄일 수 있다.
titanic.Cabin = titanic.Cabin.str[:1]
titanic.Cabin.value_counts()
titanic.Embarked.value_counts()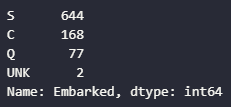
시각화
sns.countplot(x=titanic.Survived);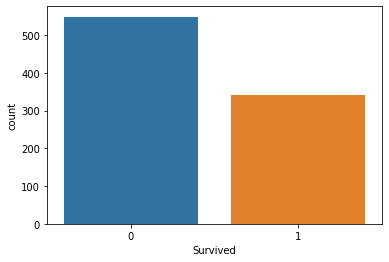
sns.barplot(x='Sex', y='Survived', data=titanic);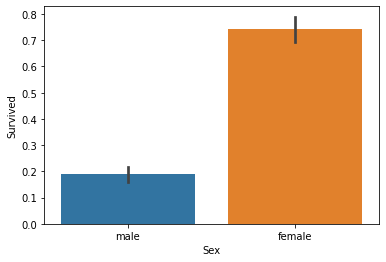
sns.barplot(x='Pclass', y='Survived', data=titanic, hue='Sex');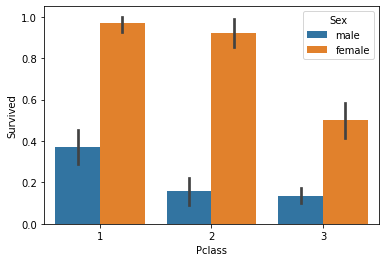
범주형 변수의 처리
FeatureEngineering의 기본은 모든 변수의 데이터를 숫자로 표현하는 것이다. 그러기 위해선 해당 변수 별로 어떤 범주의 특징을 갖고 있는지 분석하고, 범주의 특징에 알맞은 방식으로 인코딩을 진행하는 것이 바람직하다. 해당 예제에서는 빠른 진행을 위해 라벨인코더로 일괄 인코딩을 진행했지만, 실제 머신러닝에서는 되도록이면 사용하지 않는 것이 좋다. 라벨인코더는 자체적으로 변수를 sorting하여 순서대로 번호를 메기는 방식으로 인코딩하기 때문에, 어떤 변수에 어떤 특징이 있는지는 감안하지 않고 인코딩하게 된다. 그렇게 되면 머신러닝을 통해 학습시킬 때, 각각의 범주에 대해 의도하지 않은 방식으로 확대해석이나 축소해석을 하게 될 수 있기 때문이다.
from sklearn.preprocessing import LabelEncoder
cols = ['Sex','Cabin','Embarked']
for col in cols:
le = LabelEncoder()
titanic[col] = le.fit_transform(titanic[col])
print(le.classes_)
titanic.head()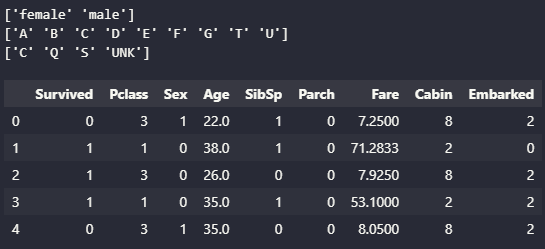
y = titanic.Survived
x = titanic.drop('Survived', axis='columns')
np.random.seed(1234)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt = DecisionTreeClassifier()
dt.fit(x_train, y_train)
pred = dt.predict(x_test)
accuracy_score(y_test, pred)0.7597765363128491'빅데이터분석👨💻 > Study' 카테고리의 다른 글
| 시각화 패키지로 지도 그리기 - Folium (1) | 2024.01.15 |
|---|---|
| 다변수의 관계 확인 (2) - lmplot(), Heatmap() (0) | 2024.01.11 |
| 다변수의 관계 확인 (1) - joinplot() (2) | 2024.01.10 |
| 분포 확인 그래프 (3) - violinplot() (1) | 2024.01.02 |
| 분포 확인 그래프 (2) - boxplot() (3) | 2024.01.02 |